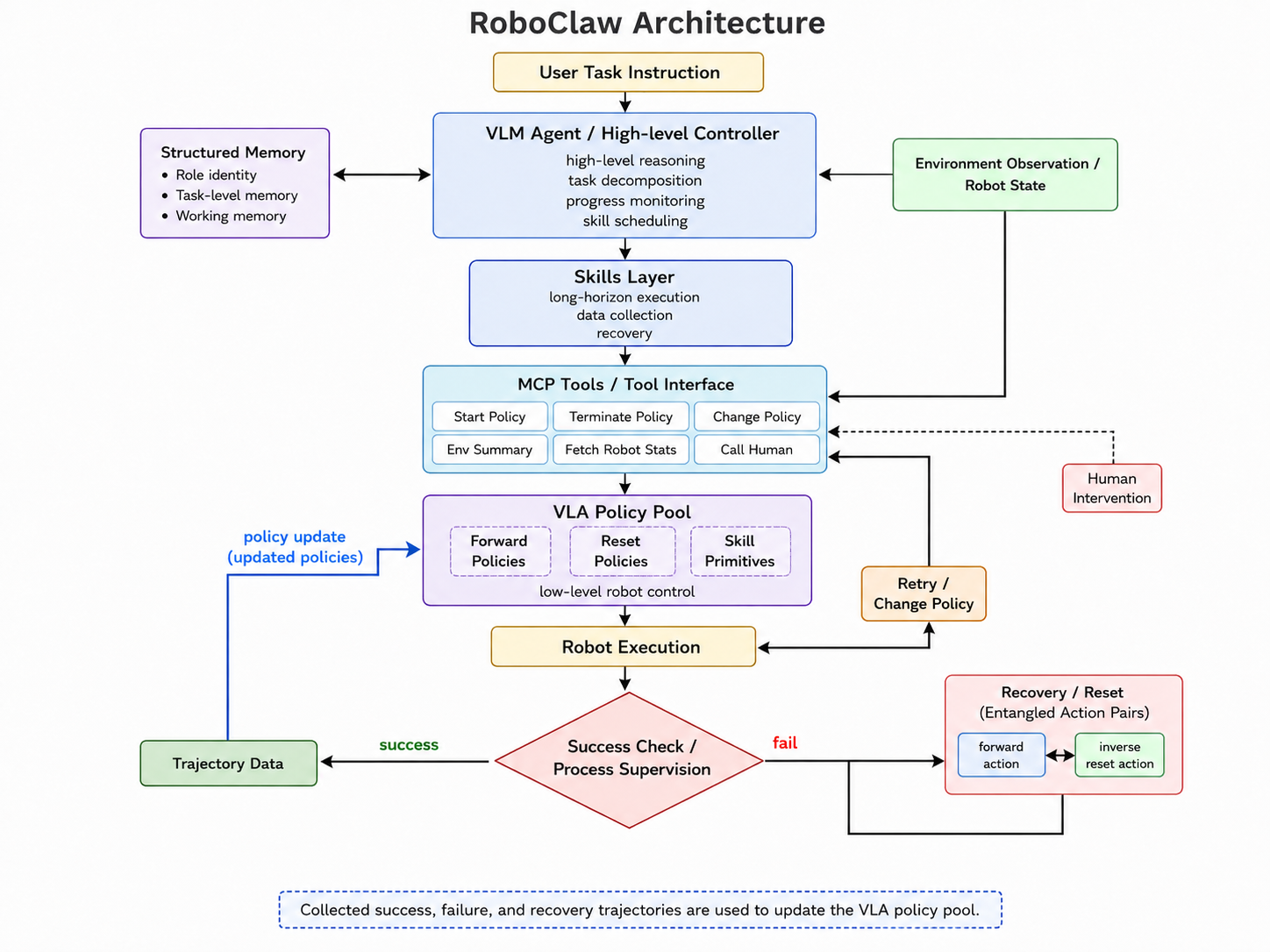
⤳Pipeline Overview
Four stages form one pipeline. scripts/run_pipeline.sh (outer repo) chains them
end-to-end: collect 50 episodes → export → train → evaluate.
flowchart TB
subgraph S1["① Data Generation (sim)"]
direction TB
A1["collect_cube_pick.py
MuJoCo + PickSkill"] A2["RawEpisodeWriter
ArmTap / GripperTap"] A3["sim_sync hook @30Hz
render 3 cams + read joints"] A1 --> A2 --> A3 end subgraph RAW["raw_episodes/"] R1["commands.parquet
observations.parquet
videos/*.mp4 + *_meta.parquet
meta.json"] end subgraph S2["② Export / Convert"] B1["export_to_lerobot.py"] B2["LeRobotExporter
30Hz timeline alignment"] B3["action[t]=state[t+1]
single-step (6,) + action_is_pad"] B1 --> B2 --> B3 end subgraph DS["LeRobot v3 dataset"] D1["meta/ · data/chunk-000
videos/observation.images.*"] end subgraph S3["③ Training"] C1["lerobot-train
SmolVLA base + LoRA r=32"] C2["chunk_size=50
bs=64 (OOM→32→16)"] C1 --> C2 end subgraph S4["④ Evaluation"] E1["eval_and_serve.py
closed-loop rollout"] end S1 --> RAW --> S2 --> DS --> S3 --> CKPT["LoRA checkpoint
pretrained_model/"] --> S4 style S1 fill:#ddf4ff,stroke:#0969da,color:#1f2328 style S2 fill:#f3eefc,stroke:#8250df,color:#1f2328 style S3 fill:#dafbe1,stroke:#1a7f37,color:#1f2328 style S4 fill:#fff8c5,stroke:#9a6700,color:#1f2328 style RAW fill:#f6f8fa,stroke:#d0d7de,color:#1f2328 style DS fill:#f6f8fa,stroke:#d0d7de,color:#1f2328
MuJoCo + PickSkill"] A2["RawEpisodeWriter
ArmTap / GripperTap"] A3["sim_sync hook @30Hz
render 3 cams + read joints"] A1 --> A2 --> A3 end subgraph RAW["raw_episodes/"] R1["commands.parquet
observations.parquet
videos/*.mp4 + *_meta.parquet
meta.json"] end subgraph S2["② Export / Convert"] B1["export_to_lerobot.py"] B2["LeRobotExporter
30Hz timeline alignment"] B3["action[t]=state[t+1]
single-step (6,) + action_is_pad"] B1 --> B2 --> B3 end subgraph DS["LeRobot v3 dataset"] D1["meta/ · data/chunk-000
videos/observation.images.*"] end subgraph S3["③ Training"] C1["lerobot-train
SmolVLA base + LoRA r=32"] C2["chunk_size=50
bs=64 (OOM→32→16)"] C1 --> C2 end subgraph S4["④ Evaluation"] E1["eval_and_serve.py
closed-loop rollout"] end S1 --> RAW --> S2 --> DS --> S3 --> CKPT["LoRA checkpoint
pretrained_model/"] --> S4 style S1 fill:#ddf4ff,stroke:#0969da,color:#1f2328 style S2 fill:#f3eefc,stroke:#8250df,color:#1f2328 style S3 fill:#dafbe1,stroke:#1a7f37,color:#1f2328 style S4 fill:#fff8c5,stroke:#9a6700,color:#1f2328 style RAW fill:#f6f8fa,stroke:#d0d7de,color:#1f2328 style DS fill:#f6f8fa,stroke:#d0d7de,color:#1f2328
⚠ The flowchart is rendered by Mermaid and needs a CDN script (network access).
Offline, follow the per-stage text below in order: collect → raw_episodes → export → LeRobot dataset → train → checkpoint → evaluate.
Data generation
Export / convert
Training
Evaluation